Synthetic Fraud Score
Flag falsified and manipulated identities.
Stop more first- and third-party synthetic fraud with higher precision and less friction.

Stay ahead of attacks
Use a model trained by internal labels to reflect evolving fraud tactics captured by our Fraud Intelligence Team.

Paint a precise picture
Identify hard-to-spot synthetics as well as other populations, such as recent immigrants and students, that other models may flag as suspicious.

Reduce investigations
Outperform high-cost, high-friction, low-performance approaches to consumer verification like document checks.
Scores
Get a precise number (and more).
Know what fraud actually looks like with a composite abuse score that targets first- and third-party synthetic fraud and reason codes that explain high and low risk factors.
- One primary score
- First and third-party fraud
- Explanatory reason codes
- Simple risk scale, from 0 to 1000

Models
Use best-in-class models for your best-in-class products.
Catch more fraud with higher precision. We train our model to target all types of synthetic fraud — based on hundreds of thousands of labels assigned by SentiLink’s internal Fraud Intelligence Team.
Fraud Intelligence Team
Add an extra layer of knowledge.
Get support from our team of fraud experts. We’ll apply our deep understanding of synthetic fraud tactics — helping your team go deeper and solve challenging cases.
Labels
Our team understands the nuances of synthetic identities to create clean, consistent, and clearly defined fraud labels.
Data sources
Drive outcomes with unlimited data, in one place.
Good inputs make good outputs. SentiLink’s Synthetic Fraud Score is built on our proprietary merging logic, combining highly curated data sources, our internal consortium data, and the hands-on input of our team of risk experts.
- Name
- IP address
- Address
- Phone number
- DOB
- Email address
- SSN
- Behaviors
Loading testimonials...
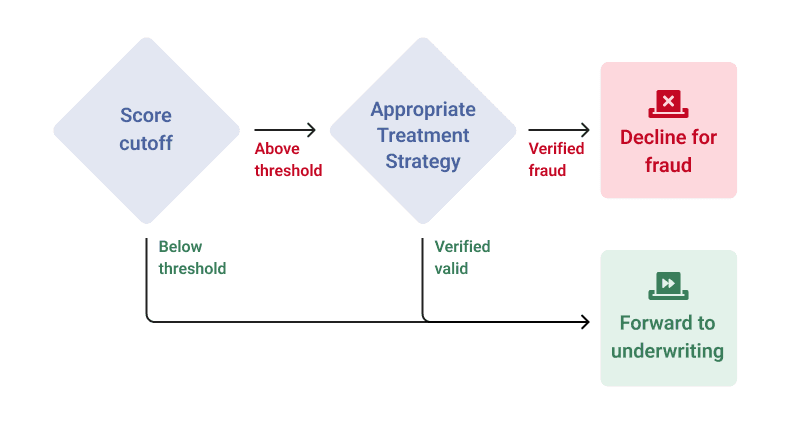
Treatment strategy
Use eCBSV to confirm suspected synthetics.
Paired with SentiLink’s Synthetic Fraud Score, eCBSV is a highly effective treatment strategy to spot synthetics from otherwise qualified thin-file applicants — reducing fraud while also making it possible to approve more legitimate consumers.
Next up
Explore more fraud and risk solutions.
ID Theft Score
Catch ID thieves in the act
Identify fraudulent applicants and reduce losses from traditional ID theft.

